目次
- 誤差
- matrix、apply
- 誤差の分布
1 誤差
歪みのないコイン投げて表が出る確率は50%です。しかし、前回書いたコードを繰り返し実行すると、コインを700回投げて表が出る確率は、毎回50%より少し高かったり低かったりします。毎回の試行で生じる真の値からのずれを誤差といいます。
700回のコイン投げを100ラウンド繰り返すと、数十ラウンドは確率が50%より高くなり、残りの数十ラウンドは確率が50%より低くなります。値がこのようにばらつくことを「誤差が分布する」といいます。分布とは、値がばらつくようすのことです。
ド・モアブルという人は、毎回のラウンドでコインを投げる回数が十分多ければ、誤差が正規分布することを発見しました。後にラプラスという人が考えを拡張しましたので、ド・モアブル=ラプラスの定理といいます。正規分布は、下図のように真ん中が高く、両端が低いつりがね状の分布です。どこかで一度はみたことがあるのではないでしょうか。
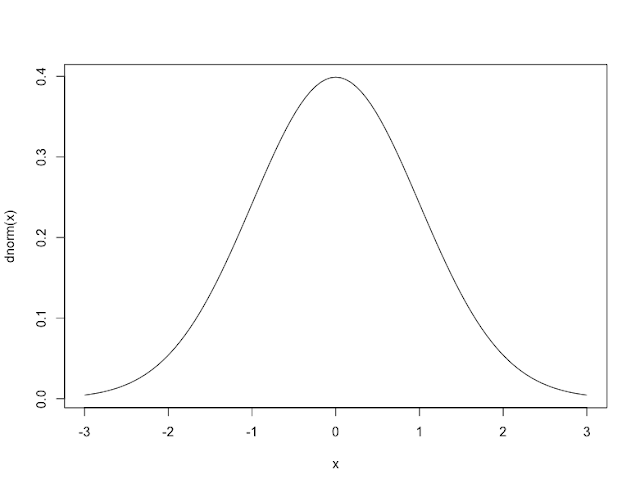
ド・モアブルという人は、毎回のラウンドでコインを投げる回数が十分多ければ、誤差が正規分布することを発見しました。後にラプラスという人が考えを拡張しましたので、ド・モアブル=ラプラスの定理といいます。正規分布は、下図のように真ん中が高く、両端が低いつりがね状の分布です。どこかで一度はみたことがあるのではないでしょうか。

ガウスという人は、コイン投げだけではなく、ほかの現象の誤差もおしなべて正規分布するとして、誤差の理論を体系化しました。それで、正規分布をガウス分布ともいいます。
誤差には公理とよばれるものが3つあります。
・小さい誤差は大きい誤差より多く観察される(単峰性)
・プラスの誤差とマイナスの誤差の起こりやすさは等しい(対称性)
・とても大きい誤差はほとんど観察されない(外れ値)
正規分布は、これら3つの条件をよく満たす特別な分布です。それで統計学に繰り返し登場します。何年か前に『統計学が最強の学問である』という本がベストセラーになりました。「統計学は誤差の科学である」と言ったほうが、専門家は喜ぶかもしれません。
誤差には公理とよばれるものが3つあります。
・小さい誤差は大きい誤差より多く観察される(単峰性)
・プラスの誤差とマイナスの誤差の起こりやすさは等しい(対称性)
・とても大きい誤差はほとんど観察されない(外れ値)
正規分布は、これら3つの条件をよく満たす特別な分布です。それで統計学に繰り返し登場します。何年か前に『統計学が最強の学問である』という本がベストセラーになりました。「統計学は誤差の科学である」と言ったほうが、専門家は喜ぶかもしれません。
正規分布については Gauss, Carolo Friderico著, 飛田武幸・石川耕春訳『誤差論』紀伊國屋書店, 1981年 を参照してください。
2 matrix、apply
コードを効率よく書くのに、行列はとても便利です。プログラミングで行列とは、エクセルの表をコードにしたものと思ってください。数のならびを行列にしておくと、繰り返し作業がかんたんにできます。
たとえば、コードを次のように書くと、コインを3回投げる試行を2ラウンド行った結果を2行3列の表にできます。1行目は前回説明したコイン投げの命令文です。2行目はコイン投げの結果をつづら折りにして2行3列の表に格納する命令文です。
toss=sample(x=c(0,1), size=2*3, replace=TRUE)
toss=matrix(toss, nrow=2, ncol=3)
たとえば、{1, 1, 1, 0, 0, 1} というコイン投げの結果は
1, 1, 0
1, 0, 1
と折り込まれます。列に方向に3回折り込む感じです。つづいて、折り込んだコイン投げの結果を行方向に足しあげ、各回までの確率を計算します。コードを次のように書くとこの作業ができます。1行目は作成した toss という名前の行列を1行ごとに足し上げる命令文です。apply は、これまで数列に利用してきた cumsum という関数を行列に適用するためのものです。第2要素の 1 は行別に足し上げる指定です。
toss=apply(toss, 1, cumsum)
上の行列を行別に足し上げると次のようになります。
1行目 1, 2, 2
2行目 1, 1, 2
さらに、次の命令文で、足しあげた数を足し上げる回数で割ります。
toss=toss/(1:3)
(1:3) は {1, 2, 3} です。これで1行目、2行目の結果を割ると
1行目 1, 1, 0.6666
2行目 1, 0.5, 0.6666
* * *
2 matrix、apply
コードを効率よく書くのに、行列はとても便利です。プログラミングで行列とは、エクセルの表をコードにしたものと思ってください。数のならびを行列にしておくと、繰り返し作業がかんたんにできます。
たとえば、コードを次のように書くと、コインを3回投げる試行を2ラウンド行った結果を2行3列の表にできます。1行目は前回説明したコイン投げの命令文です。2行目はコイン投げの結果をつづら折りにして2行3列の表に格納する命令文です。
toss=sample(x=c(0,1), size=2*3, replace=TRUE)
toss=matrix(toss, nrow=2, ncol=3)
たとえば、{1, 1, 1, 0, 0, 1} というコイン投げの結果は
1, 1, 0
1, 0, 1
と折り込まれます。列に方向に3回折り込む感じです。つづいて、折り込んだコイン投げの結果を行方向に足しあげ、各回までの確率を計算します。コードを次のように書くとこの作業ができます。1行目は作成した toss という名前の行列を1行ごとに足し上げる命令文です。apply は、これまで数列に利用してきた cumsum という関数を行列に適用するためのものです。第2要素の 1 は行別に足し上げる指定です。
toss=apply(toss, 1, cumsum)
上の行列を行別に足し上げると次のようになります。
1行目 1, 2, 2
2行目 1, 1, 2
さらに、次の命令文で、足しあげた数を足し上げる回数で割ります。
toss=toss/(1:3)
(1:3) は {1, 2, 3} です。これで1行目、2行目の結果を割ると
1行目 1, 1, 0.6666
2行目 1, 0.5, 0.6666
となります。前回、700回コインを投げる試行を1度だけやりました。今回それを拡張して、n 回コインを投げる試行を r 回繰り返します。matrix と apply を使えば、複合的な試行を繰り返すコードをかんたんに書くことができます。
* * *
3 誤差の分布
誤差が正規分布するかRで検証しましょう。下図のコードを入力して実行してみてください。これくらいの長さのコードが数回つづいていますので、だんだん入力に慣れてきたのではないでしょうか。

うまくいけば、右下の領域に次のような4枚のグラフがあらわれます。なかなか壮観ですね(ここでは一覧性を高めるために4つまとめて表示していますが、上のコードでは4枚別々のグラフになります。)

(par(mfrow = c(2, 2)) を使うとまとめて表示できます)
* * *
以下、準備、処理、出力の順に説明します。まず準備からです。2行目と3行目はいつものおまじないです。4行目は毎回のラウンドでコインを投げる回数、5行目はコイン投を繰り返すラウンド数を指定しています。このコードでは、コインを1000回投げる試行を100ラウンド繰り返します。

* * *
つづいて処理です。7行目は $n\times r$ 回コインを投げた結果をならべる命令文です。この命令文は前回と同じものです。8行目はコイン投げの結果を r 行 n 列の行列に格納する命令文です。
9行目は行列に格納されたコイン投げの結果を、行ごとに足し上げる命令文です。上で説明したように、apply は、数列に使う関数を行列でも使えるようにする魔法の関数です。第2要素の 1 は、第3要素の cumsum という関数を行に適用するという指定です。(2 にすると、列方向に関数を適用する指定になります。)
9行目までで、それぞれのラウンドの n 回目までに表が出た回数が計算されました。10行目は、9行目で再定義した toss をコインを投げる回数で割っています。10行目で再定義される toss はそれぞれのラウンドの n 回目までに表が出た確率(相対頻度)を表します。
12行目は、それぞれのラウンドで n 回まで投げ終わったときの確率の平均を計算しています。Rでは mean で平均を計算します。13行目は、それぞれのラウンドで n 回まで投げ終わったときの確率の標準偏差を計算しています。Rでは sd で標準偏差を計算します。
行列表記して apply を使うと、計算効率が飛躍的に高まります。

* * *
さいごに出力です。15行目は、コイン投げのようすを r ラウンド分まとめてグラフにするとてつもなく便利な命令文です。このコードでは、100回分のグラフ(サンプルパス)を瞬時に描くことができます。上に掲げた左上のグラフがこの1行で描けます。
17行目と18行目は、12行目の計算結果(平均の収束)をグラフにする命令文です。上に掲げた右上のグラフに対応します。20行目から22行目は、13行目の計算結果(標準偏差の収束)をグラフにする命令文です。上に掲げた左下のグラフに対応します。
24行目と25行目は、毎回のラウンドでコインを n回投げ終わったときの確率がどのように分布しているか、ヒストグラムで表したものです。点線のグラフは正規分布のグラフです。ヒストグラムは正規分布に近い形をしています。
Rでは、4つのグラフを描くのに10行のコードで済みます。

「まったくおなじ条件で、まったくおなじ実験を、とてもたくさん繰り返す」とき、誤差は平均0、標準偏差 $\sigma/\sqrt{n}$ の正規分布にしたがいます。これを中心極限定理といいます。
中心極限定理はとても難しい統計学の定理です。しかし、今回のコードを実行して得られる4つのグラフから、「まったくおなじ条件で、まったくおなじ実験を、とてもたくさん繰り返す」と、誤差は正規分布することを感じていただけるのではないでしょうか。
補論 中心極限定理を理解するコツ
中心極限定理は「どんな分布も、正規分布になる」と軽く説明されることがあります。たとえば、「上段の一様分布が下段の正規分布になる」などと聞いたりします。(そんな説明あり得ないという人は、そう聞こえている、と読み替えてください。)

⇩

このような説明を聞いてはじめ「???」だったのですが、真の平均からのずれ(誤差)が正規分布すると知って「なんだ、そいういうことか」と思えました。
コインを2回だけ投げて表が出る確率の誤差より、コインを1000回投げて表が出る確率の誤差が、真の確率50%付近に集まるのは自然なことです。サイコロを2回だけ振って出た目の平均の誤差より、サイコロを1000回振って出た目の平均の誤差が、真の平均3.5近くに集まるのは自然なことです。
考えてみれば当たり前ですが、一様分布が正規分布になるはずありません。正規分布になるのは一様分布ではなく、一様分布からランダムに取り出した値の平均と一様分布の真の平均とのずれ、すなわち誤差です。中心極限定理は誤差のことと強調しないとはじめての人は混乱しますよね…













































{kind=link}